How to Write An Assembler in Racket, Part 2: Architecture Overview
02 Jun 2022
Reading time ~7 minutes
Architecture Overview
Last time, I wrote about my motivation to create a new assembly toolchain for cross-development targeting older architectures like Z80 or 6502. In this article, I’ll describe the overall architecture of Wyvern. How it will deviate from classical multi-pass assemblers and why. I’ll just start with 65C02 as it is a small enough instruction set that I can present as a whole here. But I ultimately want support (including but not limited to) Z80, 68k, and 6809 for some platforms I’d like to target someday.
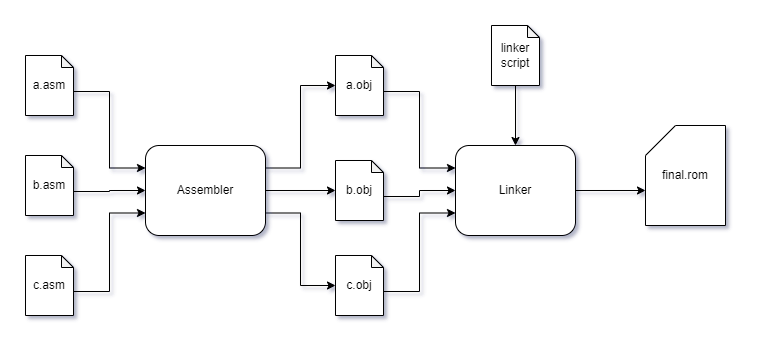
Now, that’s a very simple high-level view, but shows one important thing: There’s no way to avoid the linker. The assembler will translate each individual assembly file/translation unit into object files. The linker will then take all these object files and use a linker script to create the final ROM or binary.
In this article, we’ll mainly talk about the assembler, the linker will have to wait a little bit longer. We’ll look at the three parts that will make up the assembler, and what their individual tasks are.
The Assembler
The main job of the assembler is to take a (hopefully, valid) input file and turn it into an object file. As the target format, I plan to use ELF. The linker will then take said object files to create the final binary.
The assembler is made up of three basic parts and the symbol table, which is a bit special and will have its own post.
Keep in mind this is just a high-level overview. We’ll look at each part’s functionality in more detail once we start implementing them. Let’s look at all three stages individually.
The Scanner
The scanner’s job is to take an input stream of characters (aka, the source file) and turn it into a stream of lexemes. This step in a compiler toolchain is generally called lexical analysis. The scanner is sometimes also called lexer or tokenizer. The goal is to group characters into lexemes that the next step, the parser, can understand.
A lexeme is a tuple made up of a token type and an attribute or token value, we’ll represent this simply as tuple (token-type, attribute-value). Token types can be syntactical categories like identifier, number, function call, etc.
Let’s look at a simple example. Suppose we have this input source stream:
Start:
mov a, 12
inc a
inc a
We want to turn this into a stream of lexemes. Depending on how we define our syntactical categories, this could be one possible result:
(Identifier, "Start")
(Mnemonic, "mov")
(Register, "A")
(Comma)
(UnsignedInteger, 12)
(Mnemonic, "inc")
(Register, "A")
(Mnemonic, "inc")
(Register, "A")
Note how the scanner simply mechanically translates the input stream into lexemes. We’re not interested yet in checking whether this program is valid or not (“is it a legal command to increment register A?”). That’s the parser’s job in the next section.
Another important thing to note is that the attribute value is not always necessary. In our example, it is sufficient to capture the fact that a , (comma) has been found in the stream since this will (in the case of 6502 assembly) separate the operands of a given mnemonic or opcode. When and how to capture attribute values, is up to the scanner’s designer. For example, we could also capture each mnemonic individually:
(Identifier, "Start")
(MOVMnemonic)
(RegisterOperand, "A")
(Comma)
(UnsignedInteger, 12)
(INCMnemonic)
(RegisterOperand, "A")
(INCMnemonic)
(RegisterOperand, "A")
In general, we want to keep the number of syntactical categories as low as is practical. That is obviously a bit vague, but it really depends on the kind of (programming) language you’re trying to scan. Assembly languages can vary from a few dozen commands (70 in the case of a 65C02) and registers for simple CPUs, up to several thousand instructions for a modern instruction set architecture. Still, scanners are usually the part that changes least often, even with constantly evolving languages like C++ or Python. Later stages will be more efficient in turning this lexeme or token stream into a full abstract syntax tree.
Once our scanner has transformed the input source file or stream into a lexeme stream, we hand it off to the parser.
The Parser
Next, we need to transform the lexeme stream into an abstract syntax tree. This step is also called syntactical analysis. To translate the incoming lexeme stream into an AST, the parser needs a description of the language in the form of a context-free grammar. We’ll develop our CFG for our assembler in a later article. There, we’ll also look in more detail into CFGs in general.
Let’s look at a very simplified example CFG for a subset of Z80 assembly:
\[\newcommand{\T}[1]{\texttt{#1}} \newcommand{\pro}{\quad \to \quad} \newcommand{\or}{\quad \; \mid \quad} \begin{alignat*}{3} &Program &&\pro &&Lines \\ \\ &Lines &&\pro &&Identifier \quad \T{:} \\ & &&\or &&Mnemonic \quad Register \\ & &&\or &&Mnemonic \quad Register \quad \T{,} \quad Number \\ \\ &Mnemonic &&\pro &&\T{mov} \\ & &&\or &&\T{inc} \\ \\ &Register &&\pro &&\T{a} \\ \\ &Number &&\pro &&\T{any valid unsigned number} \\ \\ &Identifier &&\pro &&\T{any valid alphanumeric string} \\ \\ \end{alignat*}\]Again, this is very simplified for demonstration purposes. We’ll go into more detail about CFGs when we start implementing the parser. For now, you only need to know that a CFG is made up of so-called production rules, nonterminals, terminals and a starting symbol (which is a nonterminal). A production rule determines how a nonterminal symbol on the left of the arrow can be replaced with a combination of terminals and nonterminals. It is conventional to start nonterminals with an upper-case letter, and terminals with lower-case letters. We’ll follow this convention. Here’s an important thing to remember: The terminal symbols of our CFG match the lexemes our scanner can produce.
Program is called the start symbol of our CFG. This will be the root of the AST we’re going to build. In essence, the problem we’re trying to solve can be visualized thus:

In essence, we’re trying to build a tree with the start symbol as its root and the lexeme stream (produced by the scanner) as its leaves. There are two basic strategies employed: top-down parsing and bottom-up parsing. Both methods have their pros and cons, it is a huge field of study too big to cover here. Suffice to say, I’ll cover recursive descent parsing and parser combinators in a later article since this is what Wyvern will use.
Once our parser has run, we should have a tree structure that represents our program:

If the parser is unable to construct an AST from the lexeme stream, then the syntactical analysis has failed - that’s the SYNTAX ERROR! your compiler keeps yelling at you about.
Mind that this is very simplified. We haven’t seen anything resembling subroutines, conditionals, macros, etc. We’ll cover these more advanced topics when we construct the CFG for our assembler.
Finally, the generator will turn our AST into the object file we want.
The Generator
The final step in the assembler is code generation, also semantic analysis. The generator will take the AST and translate all instructions into the corresponding machine code. Both the machine code and all the symbols defined in that file will be encoded in the output object file, in ELF format.
(In terms of compiler design, this would be the step where the intermediate representation is generated and passed to the backend of the compiler - which then in turn generates the assembly and machine code. We can “skip” that since we already have the assembly code.)
This is (for now at least) a rather mechanical step that is easier explained when we get to the actual implementation. Just remember that the generator will turn the abstract syntax tree into the ELF file the linker will then use to put together the final binary.
The Linker
The linker is going to get its own article in the future. So here’s only a high-level overview. Once the assembler is done, the object files will be
- relocatable, which means the memory addresses where symbols, instructions, subroutines, etc. reside have not yet been determined, and
- unlinked, meaning that any references to external subroutines, symbols, etc. have not yet been resolved.
Conclusion
This was a basic overview of how the three main parts of the assembler - scanner, parser, and generator - will work. We’ve seen how those three parts will interact, the input they process and the output they’ll produce.
Next time, we’ll start designing the context-free grammar for the 65C02 instruction set.